


Pythonを利用したデータ分析を学ぶために、サッカーの試合データを題材にしたいと思います。
データを収集するための手段は様々ありますが、Webサイト上のデータを収集する場合には、Pythonを利用したWebスクレイピングがおススメです。
今回は、JavaScriptが利用されていない静的なWebページ上のデータ収集を行う方法を紹介していきます。
手順は次の通りです。
- Pythonライブラリ(requests、BeautifulSoup)をインストールする
- WebページのHTMLデータを取得、解析する
- HTMLの中から必要な情報を抽出する
- データフレーム化する
- データの前処理を行う
- データ型の定義を行う
早速コードを書いていきます。
#ライブラリをインストールする
import requests
from bs4 import BeautifulSoup今回紹介する方法では、次の2つのPythonライブラリを利用します。
- requests・・・指定したURLのWebページのHTMLデータを取得してくれる
- BeautifulSoup・・・複雑な構造のHTMLデータを解析してくれる
今回は、データスタジアム株式会社様の運営するFootball LAB(https://www.football-lab.jp/)からJリーグの試合を1つ取り上げてデータ収集の手順を紹介していきます。
#URLを変数に格納する
match_url = "https://www.football-lab.jp/y-fm/report/?year=2022&month=02&date=19"
#HTMLを取得して変数に格納する
match_html = requests.get(match_url).text実際にrequestsで取得したHTMLデータの中身を見てみましょう。
print(match_html) #HTMLの中身を見てみる<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:fb="http://www.facebook.com/2008/fbml">
<head>
<meta http-equiv="Content-Language" content="ja" />
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" /><meta http-equiv="X-UA-Compatible" content="IE=edge"/>
<meta http-equiv="Content-Style-Type" content="text/css" />
<meta http-equiv="Content-Script-Type" content="text/javascript" />
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="robots" content="index,follow" /><title>横浜F・マリノス 2022マッチレポート | 2月19日 vs C大阪 | データによってサッカーはもっと輝く | Football LAB</title>
<meta name="keywords" content="サッカー,Jリーグ,データ,ランキング,フットボールラボ,Football LAB,チャンスビルディングポイント,CBP,J1,J2,J3,横浜F・マリノス,マッチレポート,ゲームレポート,レポート,試合" />
<meta name="description" content="フットボールラボ(Football LAB)はサッカーをデータで分析し、新しいサッカーの観戦方法を伝えるサッカー情報サイトです。選手のプレーを評価するチャンスビルディングポイントやプレースタイル指標、チームの戦術を評価するチームスタイル指標といった独自のデータを開発しています。データを活用してサッカーに新しい視点を提供するとともに、レポートやコラムを通してJリーグの試合を分析・解説します。" />
・・・HTMLデータを取得できていることを確認できました。
続いて、取得したHTMLデータをBeautifulSoupで解析します。
#HTMLデータの解析結果を変数に格納する
match_soup = BeautifulSoup(match_html, 'html.parser')ここまででデータを取得するための下準備が完了しました。
ここからは、実際に取得したいデータがHTML上でどこに位置しているかを確認し、BeautifulSoupの解析結果から抽出していきます。
まず、試合の基本データを抽出していきます。Webページ上の該当箇所を確認します。

まずは、上部の試合結果のHTMLを確認します
<tr>
<td class="tName r"><span><a href="/y-fm/">横浜F・マリノス</a></span></td>
<td class="numL c">2</td>
<td class="numL c">-</td>
<td class="numL c">2</td>
<td class="tName l"><span><a href="/c-os/">セレッソ大阪</a></span></td>
</tr>この中から「横浜F・マリノス」「2」「2」「セレッソ大阪」の4箇所を抽出していきます。
#チーム名の部分を抽出
teams = match_soup.find_all("td", class_="tName")
#ホームチームを抽出
team_home = teams[0].text
#アウェイチームを抽出
team_away = teams[1].text
#ゴール数の部分を抽出
goals = match_soup.find_all("td", class_="numL")
#ホームチームのゴール数を抽出
goal_home = goals[0].text
#アウェイチームのゴール数を抽出
goal_away = goals[2].text抽出結果を確認します。
print(team_home)
print(team_away)
print(goal_home)
print(goal_away)横浜F・マリノス
セレッソ大阪
2
2続いて、下部の基本情報のHTMLコードを確認します
<div class="boxHalfSP l">2022.2.19 14:00 Kick Off</div>
<!---->
<div class="boxHalfSP r">日産スタジアム</div>
<!-- 環境情報 -->
<div class="infoList">
<dl><dt>天気</dt><dd>曇</dd></dl>
<dl><dt>気温</dt><dd>9℃</dd></dl>
<dl><dt>芝</dt><dd>全面良芝</dd></dl>
<dl><dt>観客数</dt><dd>13,737<span class="s">人</span></dd></dl>
</div>この中から「2022.2.19 14:00 Kick Off」「日産スタジアム」「曇」「9℃」「全面良芝」「13,737」の5箇所を取得していきます。
#日時、場所の部分を抽出する
info = match_soup.find_all("div", class_="boxHalfSP")
#リストの1番目に格納されている「日付」を変数に格納する
date = info[0].text
#リストの2番目に格納されている「場所」を変数に格納する
location = info[1].text
#天気、気温、芝、観客数の部分を抽出する
info2 = match_soup.find("div", class_="infoList")
info2 = info2.find_all("dd")
#リストの1番目に格納されている「天気」を変数に格納する
weather = info2[0].text
#リストの2番目に格納されている「気温」を変数に格納する
temp = info2[1].text
#リストの3番目に格納されている「芝」を変数に格納する
grass = info2[2].text
#リストの4番目に格納されている「観客数」を変数に格納する
audience = info2[3].text抽出結果を確認します。
print(date)
print(location)
print(weather)
print(temp)
print(grass)
print(audience)2022.2.19 14:00 Kick Off
日産スタジアム
曇
9℃
全面良芝
13,737人ここまでの抽出結果をデータフレームに変換します。
#ライブラリをインストールする
import pandas as pd
import numpy as npdf_info = pd.DataFrame(
data={'日付': [date],
'場所': [location],
'天気': [weather],
'気温(℃)': [temp],
'芝': [grass],
'観客(人)': [audience],
'ホームチーム': [team_home],
'アウェイチーム': [team_away],
'ホーム得点': [goal_home],
'アウェイ得点': [goal_away]}
)作成したデータフレームを確認します。
df_info
ここまでで試合の基本情報の抽出~データフレーム作成までが完了しました。
続いて、試合のスタッツを抽出していきます。Webページ上の該当箇所を確認します。
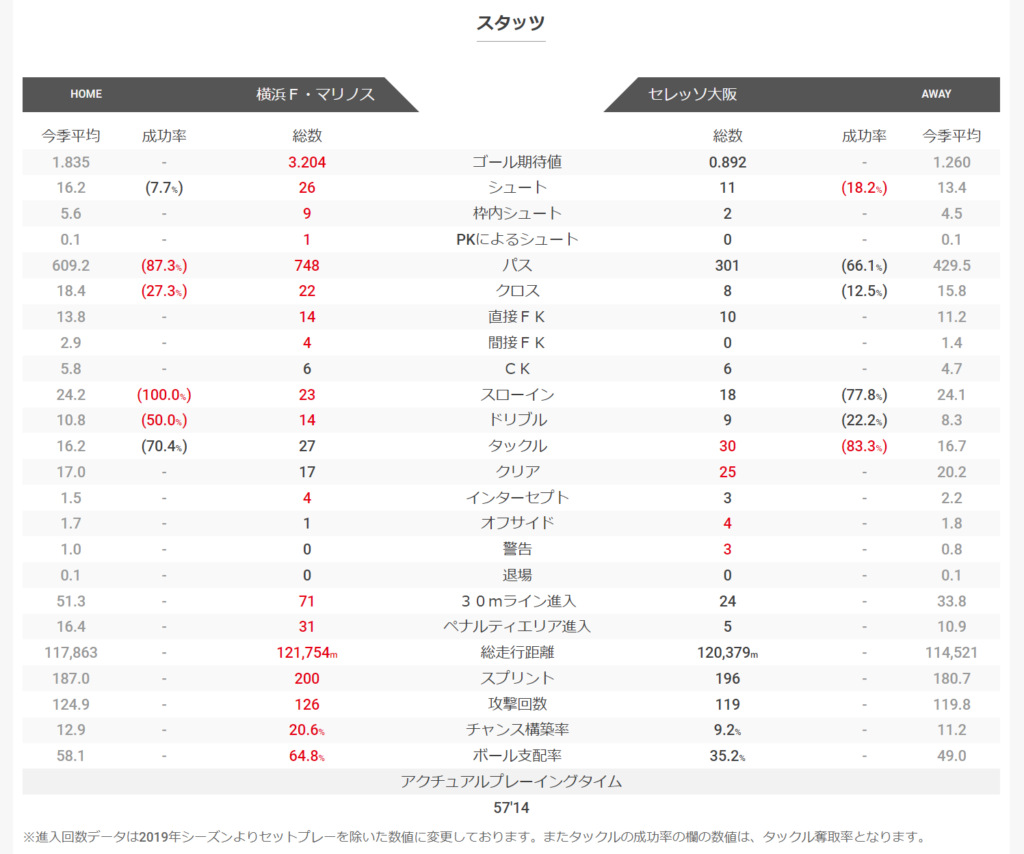
該当箇所のHTMLコードを確認します。
<table class="statsTbl6">
<thead>
<tr>
<th class="dsktp">今季平均</th>
<th class="">成功率</th>
<th class="">総数</th>
<th class="dsktp"></th>
<th class="">総数</th>
<th class="">成功率</th>
<th class="dsktp">今季平均</th>
</tr>
</thead>
<tbody>
<tr class="tr3 sp"><td colspan="4">ゴール期待値</td></tr>
<tr class="tr2">
<td class="dsktp numNA c">1.835</td>
<td class="c numNA">-</td>
<td class="c num1st">3.204</td>
<td class="dsktp c">ゴール期待値</td>
<td class="c">0.892</td>
<td class="c numNA">-</td>
<td class="dsktp numNA c">1.260</td>
</tr>
・・・テーブル内のデータを抽出していきます。
#テーブルを特定し変数に格納する
tables = match_soup.find_all("table", class_="statsTbl6")
table = tables[1]
#テーブル内に複数存在するtdタグを全て抽出する
td_tags = table.find_all("td")
#配列を用意して抽出したtdタグ内のテキストデータを格納する
stats = []
for td_tag in td_tags:
stats.append(td_tag.text)stats_home_num = stats[3::8] #ホームチームの総数を格納する
stats_home_per = stats[2::8] #ホームチームの成功率を格納する
stats_away_num = stats[5::8] #アウェイチームの総数を格納する
stats_away_per = stats[6::8] #ホームチームの成功率を格納する
#ひとつの配列にまとめる
stats_all = stats_home_num + stats_home_per + stats_away_num + stats_away_per
#データフレームに変換する
df_stats = pd.DataFrame([stats_all])作成したデータフレームを確認する。

stats_columns = stats[0::8] #データ項目名を格納する
#カラム名が格納された配列を作成する
columns = []
for stats_column in stats_columns:
column_name = str(stats_column) + "_Home"
columns.append(column_name)
for stats_column in stats_columns:
column_name = str(stats_column) + "_成功率_Home"
columns.append(column_name)
for stats_column in stats_columns:
column_name = str(stats_column) + "_Away"
columns.append(column_name)
for stats_column in stats_columns:
column_name = str(stats_column) + "_成功率_Away"
columns.append(column_name)
#データフレームにカラム名を適用する
df_stats.columns = columnsデータフレームにカラム名が適用されていることを確認する。

値の入っていない列を削除する。
#元の配列で値が入っていないインデックスを検索する
null_index = [i for i, x in enumerate(stats_all) if x == '-']
#データフレームから値の入っていない列を削除する
df_stats = df_stats.drop(df_stats.columns[null_index], axis=1)値が入っていない列が削除されていることを確認する。

基本情報のデータフレーム「df_info」とスタッツのデータフレーム「df_stats」を行方向に結合する。
#df_info、df_statsを行方向に結合する
df_match = pd.concat([df_info, df_stats], axis=1)作成したデータフレームを確認する。
df_match
1試合1レコードとするデータフレームの作成方法は以上です。
続いて、1試合について両チームの視点から2つのデータフレームを作成する方法を紹介します。
#基本情報のデータフレームをホームとアウェイそれぞれ作成する
df_info_home = pd.DataFrame(
data={'日付': [date],
'場所': [location],
'天気': [weather],
'気温(℃)': [temp],
'芝': [grass],
'観客(人)': [audience],
'チーム名': [team_home],
'対戦相手': [team_away],
'Home/Away': "Home",
'得点': [goal_home],
'失点': [goal_away]}
)
df_info_away = pd.DataFrame(
data={'日付': [date],
'場所': [location],
'天気': [weather],
'気温(℃)': [temp],
'芝': [grass],
'観客(人)': [audience],
'チーム名': [team_away],
'対戦相手': [team_home],
'Home/Away': "Away",
'得点': [goal_away],
'失点': [goal_home]}
)#スタッツの配列をホームとアウェイそれぞれ作成する
stats_home = stats_home_num + stats_home_per + stats_away_num + stats_away_per
stats_away = stats_away_num + stats_away_per + stats_home_num + stats_home_per
#データフレームに変換する
df_stats_home = pd.DataFrame([stats_home])
df_stats_away = pd.DataFrame([stats_away])stats_columns = stats[0::8] #データ項目名を格納する
#カラム名が格納された配列を作成する
columns = [] + stats_columns
for stats_column in stats_columns:
column_name = str(stats_column) + "_成功率"
columns.append(column_name)
for stats_column in stats_columns:
column_name = "(被)" + str(stats_column)
columns.append(column_name)
for stats_column in stats_columns:
column_name = "(被)" + str(stats_column) + "_成功率"
columns.append(column_name)
#データフレームにカラム名を適用する
df_stats_home.columns = columns
df_stats_away.columns = columns#元の配列で値が入っていないインデックスを検索する
home_null_index = [i for i, x in enumerate(stats_home) if x == '-']
away_null_index = [i for i, x in enumerate(stats_away) if x == '-']
#データフレームから値の入っていない列を削除する
df_stats_home = df_stats_home.drop(df_stats_home.columns[home_null_index], axis=1)
df_stats_away = df_stats_away.drop(df_stats_away.columns[away_null_index], axis=1)#df_info、df_statsを行方向に結合する
df_match_home = pd.concat([df_info_home, df_stats_home], axis=1)
df_match_away = pd.concat([df_info_away, df_stats_away], axis=1)
#df_match_home、df_match_awayを列方向に結合する
df_match = pd.concat([df_match_home, df_match_away], axis=0)df_match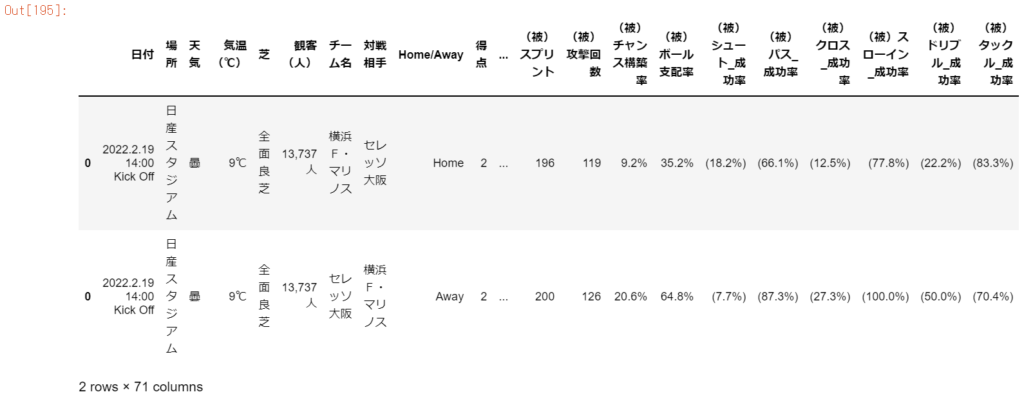
この後、データ分析がしやすいようにデータの前処理を行う。
df_match['日付'] = df_match['日付'].str[:-15] #後ろから15文字分を削除する
df_match['日付'] = df_match['日付'].str.replace('.', '/') #ドットをスラッシュに変換する
df_match['気温(℃)'] = df_match['気温(℃)'].str.rstrip('℃') #℃を削除する
df_match['観客(人)'] = df_match['観客(人)'].str.rstrip('人') #人を削除する
df_match['観客(人)'] = df_match['観客(人)'].str.replace(',', '') #カンマを削除する
df_match['総走行距離'] = df_match['総走行距離'].str.rstrip('m') #mを削除する
df_match['総走行距離'] = df_match['総走行距離'].str.replace(',', '') #カンマを削除する
df_match['(被)総走行距離'] = df_match['(被)総走行距離'].str.rstrip('m') #mを削除する
df_match['(被)総走行距離'] = df_match['(被)総走行距離'].str.replace(',', '') #カンマを削除する
df_match = df_match.rename(columns={'総走行距離': '総走行距離(m)', '(被)総走行距離': '(被)総走行距離(m)'}) #カラム名を変更する#括弧で括られているカラムを特定する
columns_per = df_match.filter(like='_成功率', axis=1).columns
for column_per in columns_per:
df_match[column_per] = df_match[column_per].str.replace('(', '') #前括弧を削除する
df_match[column_per] = df_match[column_per].str.replace(')', '') #後括弧を削除する#%で表示されているカラムを特定する
columns_per = df_match.filter(like='率', axis=1).columns.tolist()
for column_per in columns_per:
df_match[column_per] = df_match[column_per].str.replace('%', '') #%を削除する前処理後のデータフレームを確認します。

得点と失点の情報をもとに「勝ち点」の列を追加します。
#勝ち点の列を追加する
conditionlist = [
(df_match['得点'] > df_match['失点']),
(df_match['得点'] == df_match['失点']),
(df_match['得点'] < df_match['失点'])]
choicelist = ['3', '1', '0']
df_match['勝ち点'] = np.select(conditionlist, choicelist, default='Not Specified')
最後にデータ型の定義を行います。
#float型のカラム名を配列で用意する
column_float = ['気温(℃)','ゴール期待値','(被)ゴール期待値']
column_float = column_float + columns_per
#int型のカラム名を配列で用意する
column_int = ['観客(人)', '得点', '失点', 'シュート', '枠内シュート', 'PKによるシュート', 'パス', 'クロス',
'直接FK', '間接FK', 'CK', 'スローイン', 'ドリブル', 'タックル', 'クリア', 'インターセプト',
'オフサイド', '警告', '退場', '30mライン進入', 'ペナルティエリア進入', '総走行距離(m)', 'スプリント',
'攻撃回数', '(被)シュート', '(被)枠内シュート', '(被)PKによるシュート', '(被)パス', '(被)クロス', '(被)直接FK', '(被)間接FK',
'(被)CK', '(被)スローイン', '(被)ドリブル', '(被)タックル', '(被)クリア', '(被)インターセプト',
'(被)オフサイド', '(被)警告', '(被)退場', '(被)30mライン進入', '(被)ペナルティエリア進入',
'(被)総走行距離(m)', '(被)スプリント', '(被)攻撃回数', '勝ち点']
#データ型を変換する
df_match['日付'] = pd.to_datetime(df_match['日付'])
df_match[column_float] = df_match[column_float].astype('float')
df_match[column_int] = df_match[column_int].astype('int')以上、今回はPythonを使ってJリーグの試合を1つ取り上げてスタッツデータを収集する方法を紹介しました。
次回は、2022シーズンのJ1全306試合のスタッツデータを収集する方法を紹介します。