


これまで2022シーズンのJ1全306試合のスタッツデータをWebスクレイピングで収集する方法を紹介しました。
今回は、収集したデータを使ってPythonライブラリ「Pandas」の基本的な使い方を紹介します。
目次
データを読み込む
#ライブラリをインストールする
import pandas as pd
import os
#csvファイルのディレクトリを変数に格納する
wd = os.getcwd() #現在作業をしているディレクトリを取得して変数に格納する
data_dir = os.path.join(wd, "dataset") #datasetフォルダのディレクトリを作成して変数に格納する
df_stats_csv = os.path.join(data_dir, "df_stats.csv")
#csvファイルを読み込んでデータフレームを作成する
df_stats = pd.read_csv(df_stats_csv)データを確認する
先頭3行を確認する
df_stats.head(3)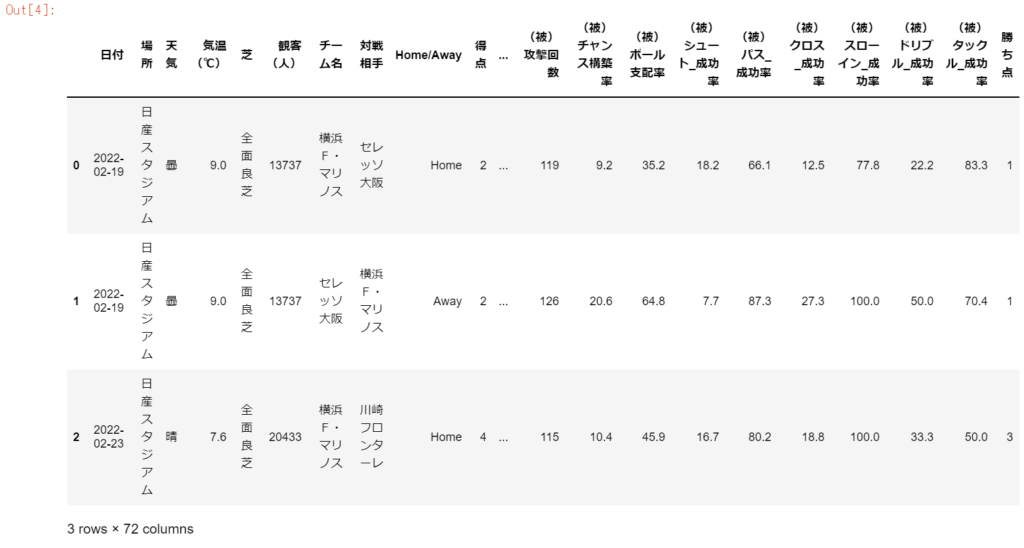
末尾3行を確認する
df_stats.tail(3)
行数、列数を確認する
df_stats.shape
カラム名を確認する
df_stats.columns
データ型を確認する
df_stats.dtypes
要約統計量を確認する
df_stats.describe()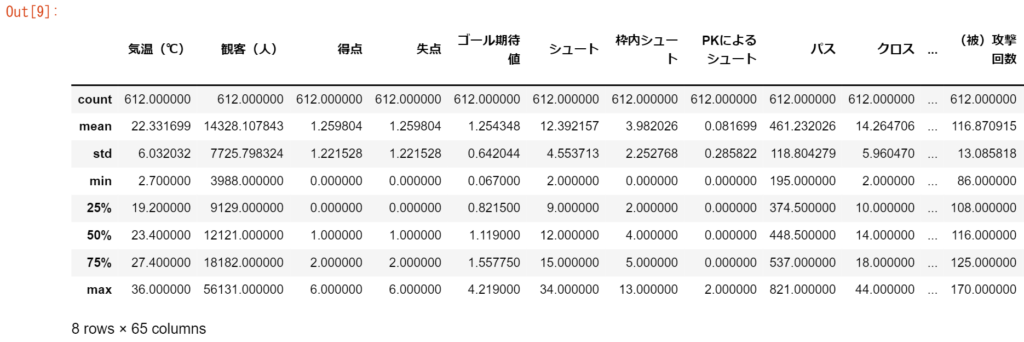
データを抽出する
行番号を指定して任意の行のみを表示する
df_stats.iloc[6] #5行目の全ての列を出力する
df_stats.iloc[2:5] #1~4行目の全ての列を出力する
df_stats.iloc[[6, 11], :] #5、10行目の全ての列を出力する
カラム名を指定して任意の列のみを表示する
df_stats[['日付', 'チーム名', '対戦相手', '勝ち点']]
列番号を指定して任意の列のみを表示する
df_stats.iloc[:, 0:11] #1~10列目までを出力する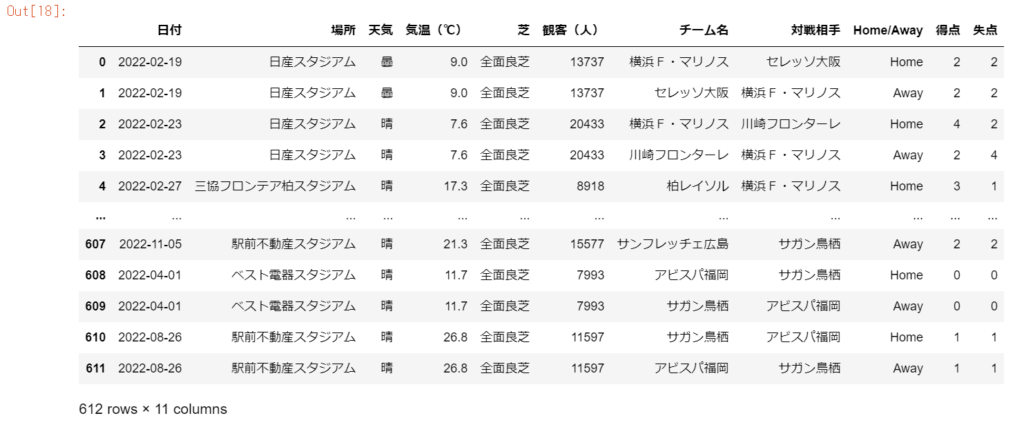
df_stats.iloc[:, [0,6,71]] #特定の列を指定して出力する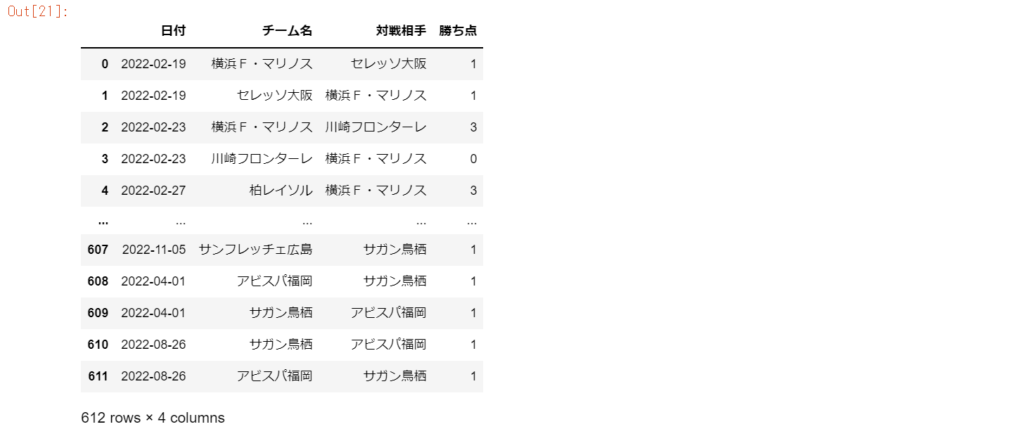
任意のインデックス名、カラム名のレコードのみを表示する
df_stats.loc[[0, 6, 11], ['日付', 'チーム名', '勝ち点']]
行番号、列番号で特定の位置の値を取得する
df_stats.iat[2, 5] #3行目、4列目の値を取得する
インデックス名、カラム名で特定の位置の値を取得する
df_stats.at[2, '観客(人)'] #3行目、4列目の値を取得する
条件を満たす行のみを表示する(queryメソッド)
df_stats.query('チーム名 == "横浜F・マリノス"') #チーム名「横浜F・マリノス」のレコードのみ取得する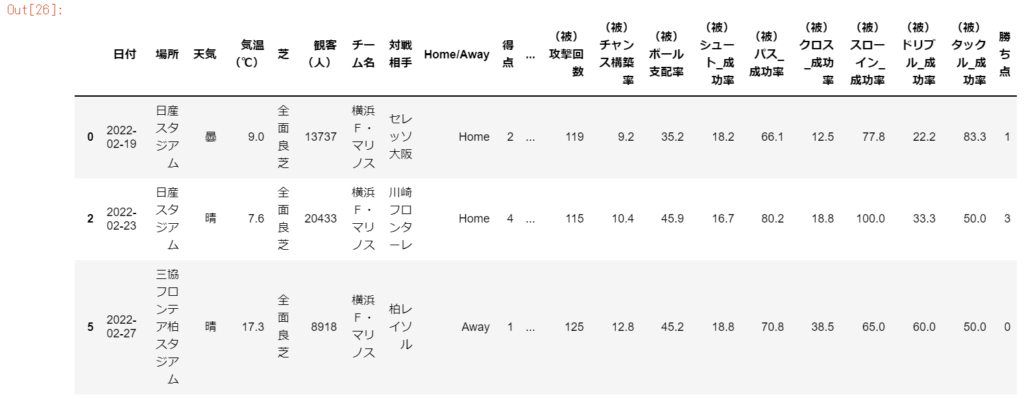
df_stats.query('チーム名 == "横浜F・マリノス" and 勝ち点 == 3') #&条件で複数指定する
df_stats.query('チーム名 == "横浜F・マリノス" or チーム名 == "川崎フロンターレ"') #or条件で複数指定する
条件を満たす行のみを表示する(queryメソッドを利用しない方法)
df_stats[(df_stats['チーム名'] == "横浜F・マリノス") & (df_stats['勝ち点'] == 3)] #横浜F・マリノスの試合かつ勝ち点3のレコードのみ取得する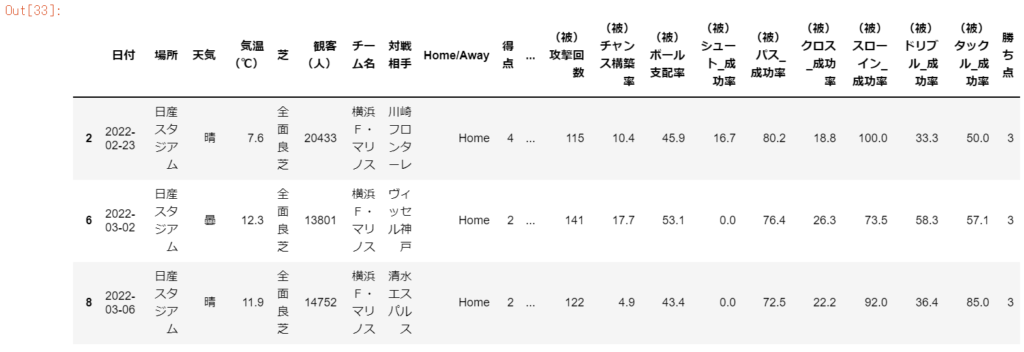
データを集計する
合計値(SUM)、平均値(MEAN)、中央値(MEDIAN)を算出する
df_stats[['チーム名','勝ち点']].groupby('チーム名').sum() #チーム別:勝ち点合計
df_stats[['チーム名','勝ち点']].groupby('チーム名').mean() #チーム別:勝ち点平均
df_stats[['チーム名','勝ち点']].groupby('チーム名').median() #チーム別:勝ち点中央値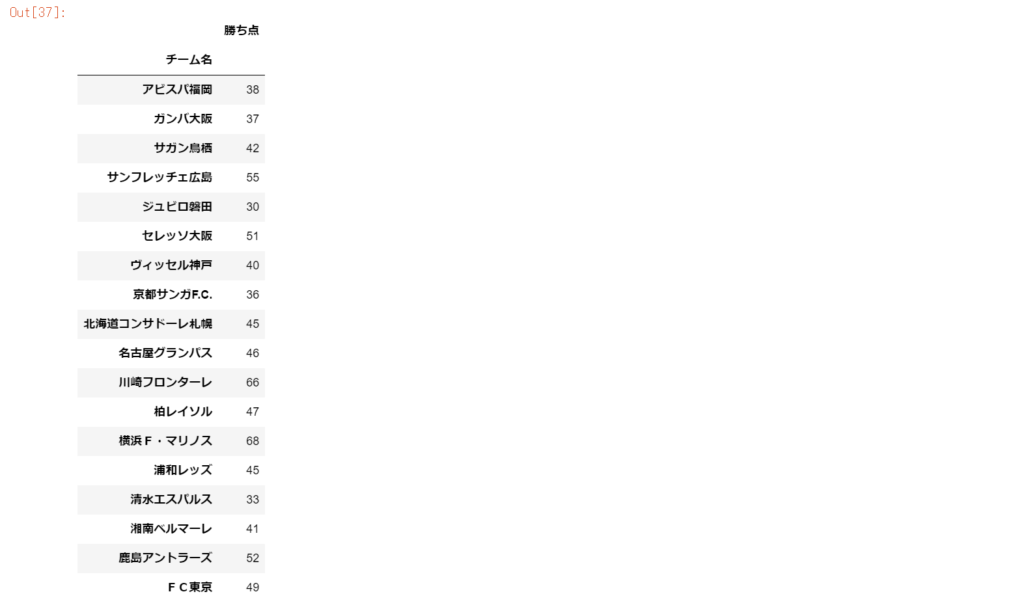
最大値(MAX)、最小値(MIN)を算出する
df_stats[['チーム名','シュート']].groupby('チーム名').max() #チーム別:シュート数の最大値
df_stats[['チーム名','シュート']].groupby('チーム名').min() #チーム別:シュート数の最小値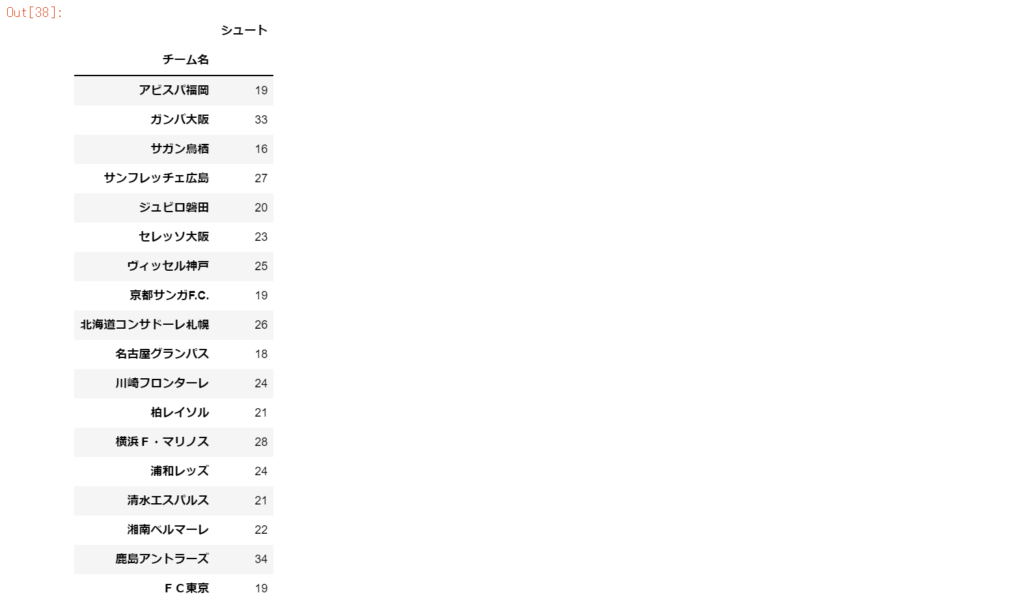
標準偏差(STD)、分散(VAR)を算出する
df_stats[['チーム名','総走行距離(m)']].groupby('チーム名').std() #チーム別:総走行距離の標準偏差
df_stats[['チーム名','総走行距離(m)']].groupby('チーム名').var() #チーム別:総走行距離の分散
値をクロス集計をする
#チーム×Home/Away別:勝ち点合計
df_stats[['チーム名', 'Home/Away', '勝ち点']].groupby(['チーム名', 'Home/Away']).sum()
値を時系列集計する
#チーム×Home/Away別:勝ち点合計
df_stats[['日付', '得点']].resample('M').sum()
件数をクロス集計する
pd.crosstab([df_stats['チーム名'], df_stats['Home/Away']], df_stats['勝敗'], margins=True)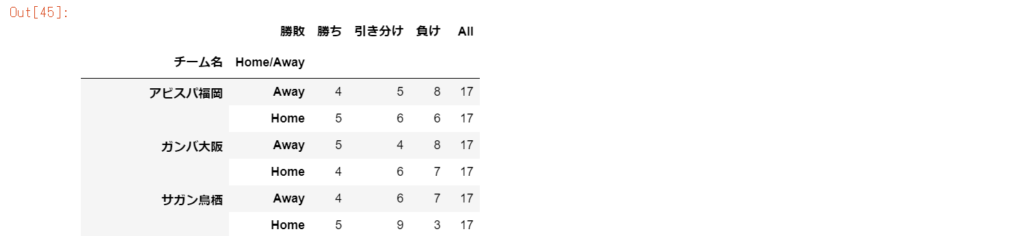
データを加工する
列同士の四則演算で新しい特徴量を作成する
df_stats['得失点差'] = df_stats['得点'] - df_stats['失点']
特定の条件に当てはまる場合に新しい特徴量を作成する①
df_stats['観客(1万人超)'] = np.where(df["観客(人)"] > 10000, 1, 0)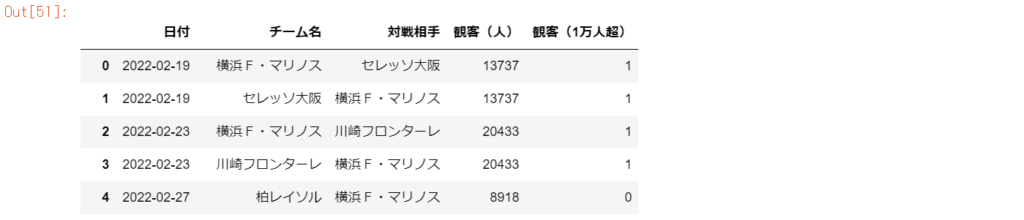
特定の条件に当てはまる場合に新しい特徴量を作成する②
conditionlist = [
(df_match['得点'] > df_match['失点']),
(df_match['得点'] == df_match['失点']),
(df_match['得点'] < df_match['失点'])]
choicelist = ['勝ち', '引き分け', '負け']
df_match['勝敗'] = np.select(conditionlist, choicelist, default='Not Specified')